
Back to LING 385
Lecture 17
Hidden representations are better representations
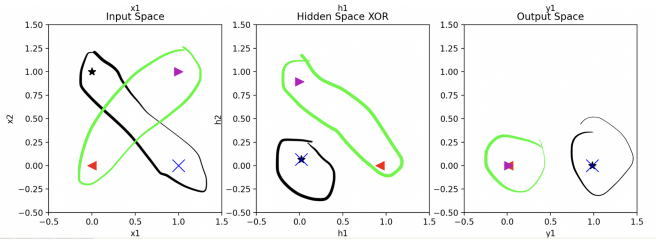
- NNs that represent "XOR" maps vectors in criss-crossing categories into vectors in their own separate categories
- embeddings = hidden representations of embedding NNs
- better representations of words than the one-hot encodings
- transforms one-hot encodings into vectors with similar numerical patterns representing grammatical similarity
- learnt by predicting words from previous words in a text
- better representations of words than the one-hot encodings
LLMs as Loss Minimization (Error-based) Learners
- LLMs are "large" because they have hundreds of NNs
- they find novel ways of learning regularities based on Loss
Two basic ways of learning from mistakes:
- BERT method: give the LLM a sentence, eliminate one or more of the words, and ask the LLM to guess what the missing words are
- GPT method: give the LLM a sequence of words, and ask it to guess the next word
- both of these ways are based in similar ways of connecting NNs
Why we need Large Language Models
- a language like English contains many dependencies that are not between contiguous words
- i.e. "The dog that they got is very cute"
- dog, not they, goes with is
- speakers of a language are very good at learning dependencies even if they're at arbitrary distances in a sentence
- knowledge in an embedding NN is not sufficient in learning all the generalizations of a language
- that's why we need LLMs, which are hundreds of NNs connected to each other
Understanding the basics of how LLMs are
structured
- LLMs are hundreds of NN's
- they try to do exactly what NNs do: transform not-so-great representations into much better representations
NNs are arranged in 2 separate ways:
- Dynamically (in series)
- as Ensembles (in parallel)
Dynamically
- an excellent representation reduces Loss much better than a terrible representation
- an LLM will have many stages of NNs, each of them produces a better representation than the one before
- each stage is called an encoder
- modern systems could have 24 or more such Encoders
Ensembles
- we could get 50 NN’s to learn randomly from the same data, each learning unique regularities
- this is called an ensemble of learners
- now we combine all of their knowledge somehow
- each of 24 the Encoders we just discussed may have an ensemble of 24 separate NN’s, each learning a different aspect of a sentence’s structure
- maybe one NN, for instance, learns about pronouns and how they refer, and another about subjects and verbs
LLM General Structure
.png)